This document is a how-to for constructing small database-driven web
projects. The techniques discussed are suited to databases stored in
Microsoft Access and which need to be updated only occasionally.
We assume that the reader has HTML skills and isn't too afraid to try basic
scripting in Perl. No foreknowledge of Perl is assumed.
The example used in this how-to is an image library, in
which an Access database storing filenames, captions and other information is
used to create web pages that list all of the entries, and also a series of
"viewer" pages in which the images are presented in a standard format.
The principles used are easily extensible to other projects.
The Challenge
Microsoft Access is the de facto standard for small and
medium-sized databases on Windows platforms. Access is, however, poorly
supported on UNIX platforms - which are the de facto standard for Web
servers - so that using a live Access database as the source of a
database-driven Web projects is troublesome. One either has to convert the
database, or source a mesh of connectors and translators. Access databases
are also poor at handling high volumes of usage, and so are unsuitable for
popular websites.
The Solution
This document proposed a two-stage solution to the challenge. First
a Perl script is run which extracts the data from the database and creates a
text-only "dump" file. Second, a Perl script is run which parses
this dump file and creates one or more web pages based on the data it finds
therein. We will give examples of both one and many pages being created by
this method.
Why not combine the scripts? It would be possible to combine
the scripts into one big do-everything script. We have chosen not to do so
because keeping the operations in discrete chunks makes it more clear, and more
simple to maintain.
Limitations
There are a few limitations to this technique:
The main limitation is that the site will not auto-update: you need to run the scripts every so often to make fresh pages. For one-offs and infrequently-updated projects, this is not a problem, but it would mean that this technique was less suitable for, say, a live calendar.
You'll need to do some Perl coding. But this is a great introduction, and Perl is an industry standard.
Before You Start: Prerequisites
You will need:
A Windows-based PC
Microsoft Access and a copy of your
database
Perl - you can download ActivePerl for Windows from ActiveState for
free. Installation is a simple follow-the-instructions job.
The Example Database
Our example database, called photos, has one table called phototable and four
fields. It looks something like this:
id
filename
alt
caption
1
happy.gif
Happy Fox
This fox is happy: he is well-fed
2
vixen.gif
Vixen
The vixen is slightly larger than the dog fox
3
images/cubs.jpg
Fox cubs, three weeks old
At three weeks, the cubs are out of the den
When we present this data, we will want a list that looks something like
this:
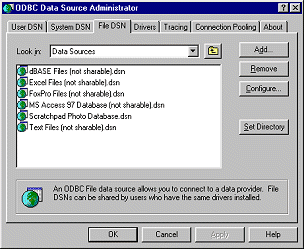
We are going to connect to the database using ODBC (Open
Database Connectivity) - a Microsoft standard for hooking databases up to other
stuff. For each database on your computer, you need to set up an
ODBC Data Source Name - commonly called a
DSN.
Here's how you create a DSN for your database:
Open the Windows Control Panel
Choose the File DSN tab. We choose File DSN rather than the others, because we
are associating this data source with the Access database file that we have.
Click Add. The Create New Data
Source wizard will start up
Choose Microsoft Access Driver from the list of database
driver types and click Next
Browse for the database file, and click
Next
Give your DSN a name - we're going to call ours photos
OK back to the Control Panel and close it
Once the DSN has been created, you can
forget it. Remember not to move the database from its current location, or
you will have to come back and tell the ODBC setup its new location.
Getting The Data Out Of The Database
The next thing to do is to get the data out of the database. We're
going to write a Perl script - a small program - to do this for
us. We shall explain any jargon bits as they come up.
Here's what we want the script to do:
Connect to the database (using the ODBC connection we
just set up)
Get the data out of the database
Build a text file with the data presented in a digestible format
Write that text file and tidy up
You can edit a Perl script in any text editor.
A few introductory notes about Perl:
Every line must end in a semicolon ;
Comments are indicated by hashes #
In a quoted text string, \n means "newline"
Save your script with a .pl extension
Connecting to the Database
The following chunk of code connects to the database and
sets up a string variable (a bucket for text) with the start of our dump.
# COMMENT: This script extracts the data in the photos
database # and writes it in a pipe-delimited text file called photos.dump
use Win32::ODBC;
# This tells Perl to load up its Windows ODBC library
my $output = "COMMENT: id|filename|alt|caption\n"; # Creates a string
called $output and writes # a first line explaining the content
$dbhl =
new Win32::ODBC("photos") || die ("Can't connect to database\n"); print ("Connected to
database.\n\n"); # Connects to the database and tells us if it succeeds or
fails
Variations on the theme:
To modify this script to work with other databases, you need to change the name of the database in the line $dbhl = new Win32::ODBC("photos") from "photos" to whatever your database is called in the ODBC DSN.
If your database has different field names, change the my $output line to reflect this.
Getting The Data Out
Nice and simple, this:
# Get rows from local table
if ( $dbhl->Sql("SELECT * FROM [phototable] ORDER BY id") ) { print $dbhl->Error() . "\n";}
Variations on the theme:
You will almost certainly need a different piece of SQL query code to get a meaningful result from your database. You can replace "SELECT * FROM [phototable] ORDER BY id" with any valid SQL statement.
SQL is a database query language. If you're not up to speed on SQL, here's a cheat. Create an Access query that shows what you want to see. Then click View » SQL View to see the SQL that Access has created behind the scenes for that query. Copy and paste that SQL into your script.
Building The Text File
This part uses a technique called iteration to do the same thing over and over to each row of the database. In this case, what we do is take bits of the database and add them together, along with other bits of text, to turn a database row into a line of text. We use a special character called a delimiter to indicate where one field ends and the next begins.
Because the "pipe" character | doesn't turn up in text very often, we are using that as our delimiter.
At the end of this process, we have a string called $output which will contain the following:
COMMENT: id|filename|alt|caption
1|happy.gif|Happy Fox|This fox is happy: he is well-fed
2|vixen.gif|Vixen|The vixen is slightly larger than the dog fox
3|cubs.jpg|Fox cubs, three weeks old|At three weeks, the cubs are out of the den
This may not be very pretty for you, but it's bread and butter for Perl to digest in later scripts.
print ("Row " . $count . " chomped.");
$count++;
print ("\n\n");
# Tells us which row it has chomped
}
Let's explain some of the Perl here.
A while loop tells Perl to continue doing the same thing as long as some condition is true. In this case, it says, "Keep doing this as long as you can fetch rows from the database." While loops are contained between a set of curly braces {} - you can see the closing brace at the foot of the code chunk. Inside the loop, we have indeted the text a little to make it easier to read.
A . between two values means "concatenate" - "Reynard" . "Fox" would come out as "ReynardFox"
.= means "take this string and add this other string on the end" - a sort of additive concatenation. If we had a string $output whose value was "Who is wily?" then $output .= "Reynard" would set $output to be "Who is wily?Reynard". The dot and dot-equals commands are used throughout our scripts to stitch together large text strings piece by piece.
When adding bits of the database, we have to consider two data types: text and numbers.
To add a number use sprintf("%03d", $data{'myfieldname'}) - the "03d" means "pad this number with zeroes to make a three-digit number".
To add text use $data{'myfieldname'}
Variations on the theme:
You will need to alter the central portion of this chunk to refer to the correct field names, in the correct order, for your database.
The counter and the printed "chomp" messages are purely optional.
Writing The Dump File
Now that we have created $output with the text we want to write, all that remains is to save it to a file and tidy up after ourselves. We need to close the database connection, and then open an output channel to which we can write our string. We finish off by closing the output channel and telling the user that all has gone well.
$dbhl->Close();
# Close the database connection
open (OUTPUT, ">./photos.dump") || die ("Can't open output file: $!");
binmode (OUTPUT);
print OUTPUT $output;
close (OUTPUT);
print ("File photos.dump successfully written!\n\n");
Again, a little more Perl to explain:
The open command opens up a file handle. We've called the file OUTPUT, and told Perl that it has a filename of "photos.dump" in the local directory.
print OUTPUT is another use of the print command. Rather than printing to the screen (which is the default), we tell it to print to the open file handle.
close closes a file handle. Don't leave them hanging - it can cause problems.
Variations on the theme:
If you want to change the filename of the dump file, simply replace "photos.dump" everywhere it appears in the script. You will need to make sure that any other scripts are looking for the right filename too, of course.
The Full Monty
Here is the full dump script, with the comments removed:
use Win32::ODBC;
my $output = "COMMENT: id|filename|alt|caption\n";
$dbhl =
new Win32::ODBC("photos") || die ("Can't connect to database\n");
print ("Connected to database.\n\n");
if ( $dbhl->Sql("SELECT * FROM [phototable] ORDER BY id") ) { print $dbhl->Error() . "\n";}
$count = 0;
open (OUTPUT, ">./photos.dump") || die ("Can't open output file: $!");
binmode (OUTPUT);
print OUTPUT $output;
close (OUTPUT);
print ("File photos.dump successfully written!\n\n");
Running The Dump Script
How do you make this script do anything? Well, you'll need a DOS box (Start » Run » command) and you'll need to be in the directory with the script. Then you just type:
perl dumpscript.pl
(or whatever you called it). Your script will then run and, if it works, will create a text file called photos.dump in the same directory.
If you make any changes to the database, you will have to re-run this script to produce a fresh dump, or your pages will become stale.
Making Web Pages From Your Dump
Okay, we have a dump of the database. Let's do something useful with it.
The basic principle here is simple: We are going to load the dump into memory, and then iterate through it, stitching together bits of HTML and bits of data. We will then save our handiwork as either one page or many.
If you have done form letters, you can do this. Honest.
Let's start with the listing. Here, we want to create a page in which we have some header information, a link for each entry with its own text, and some footer information. What we need to do is take the raw HTML, and chunk it up into bits. Then we insert the field entries, and we're sorted.
First of all, we need to load that dump file into a Perl array (a collection of strings), so that we can play with it. The code for this is:
use Win32::ODBC;
open (SOURCE, "photos.dump") || die ("Cannot open photos.dump");
my $count = 0;
while () {
print ("Parsing row " . $count . ".\n");
@fields = split( /\|/, $_ ); #Set up the data fields in a temporary array
What this does is create an array, @fields, into which is loaded each row of the dump file, one at a time. You refer to the entries in an array by their index number, so we can get the ID number by looking at $fields[0], the filename by looking at $fields[1], and so on.
Did you notice that we haven't closed the curly brace on that while statement yet? Don't worry, we'll do it later.
Chunking Up Your HTML
We are going to be making a page consisting of bits of HTML and bits of data. They will be strung together like beads on a string, HTML-data-HTML-data-HTML. So now is a good time to look at the HTML and see what chunks are what. The raw HTML for the listing is:
We've done a couple of things here. The first is that we have used single quotes ' to enclose these strings. That's because there are double quotes inside the strings, and Perl would get confused if we used them to enclose them as well. If you want to use single quotes as well - say, for an apostrophe, you need to escape it out, a jargon term meaning to precede it with a backslash: \'
The other thing we have done is remove all the newline characters. Web browsers ignore them anyway, so we have packed everything up tidily.
We can now put some of this together. The chunk definitions need to sit just before the while loop. We create the string $output at the same time. Then, inside the loop, we stitch together the bits of list and data items, using fields zero (the ID number) and two (the alt text) to make the entries. Finally, after the loop has closed, we add the footer.
use Win32::ODBC;
open (SOURCE, "photos.dump") || die ("Cannot open photos.dump");
while () {
print ("Parsing row " . $count . ".\n");
@fields = split( /\|/, $_ ); #Set up the data fields in a temporary array
$output .= $listchunk1;
$output .= $fields[0];
$output .= $listchunk2;
$output .= $fields[2];
$output .= $listchunk3;
}
$output .= $footer;
Wrapping Up
Still with us? We're almost done. All that remains now is to close the source file, open a file for output, and to write the value of $output into it. This is fundamentally the same as we did for the dump:
close (SOURCE);
open (OUTPUT, ">./list.html") || die ("Can't open output file: $!");
binmode (OUTPUT);
print OUTPUT $output;
close (OUTPUT);
Of course, if you want your file to be called something else, change the filename from list.html to whatever you like.
The Full List-Building Script
Here it is in all its glory, then - the list-building script. If you run this, after some whirring and chugging, you will get a file called list.html, which has built a linked list from the data it found in photos.dump, which in turn was created from your database.
use Win32::ODBC;
open (SOURCE, "photos.dump") || die ("Cannot open photos.dump");
We also want to create a "viewer" page for each entry. In the list, we named the links as "001.html", "002.html" and so on. We need a final script to create these pages.
Again, we're using chunked HTML to make a page string. The differences this time are:
We write the filename inside the loop
We set the filename to be a data item and string combo ($fields[0] . ".htm")
use Win32::ODBC;
open (SOURCE, "photos.dump") || die ("Cannot open photos.dump");
my $count = 0;
my $header = 'some header stuff';
my $chunk1 = 'the bit between the image filename and the image alt text';
my $chunk2 = 'the bit between the alt text and the caption';
my $footer = 'the end bit';
while () {
print ("Making page " . $count . ".\n");
@fields = split( /\|/, $_ ); # Set up the data fields
my $output = $header;
$output .= $fields[1]; # Filename
$output .= $chunk1;
$output .= $fields[2]; # Alt text
$output .= $chunk2;
$output .= $fields[3]; # Caption
$output .= $footer;
# Open a file called id.htm
# (e.g.: 001.htm) and write $output to it.
open (OUTPUT, ">./" . $fields[0] . ".htm") || die ("Can't open output file:" . $fields[0] . ".htm!\n");
binmode (OUTPUT);
print OUTPUT $output;
close (OUTPUT);
}
close (SOURCE);
When you run this script (we have left it to you to fill in the HTML chunks this time), a set of files will be created, one for each entry in the database.
In Conclusion
We have looked at extracting data from an Access database and using that data in a simple loop to build lists and sets of web pages. For most uses, this is quite adequate - no more complex programming is required, just more of the same.
The key to a great database-driven website is to use the database creatively. Maybe each of the fox pictures has a link to a page describing that aspect of foxes in great detail, or a link to the BBC Nature page.
If you start using multiple tables, you can be even more sophisticated - perhaps having a table defining "hotspots" on the images, which are built by the script by filling blanks into the <usemap> structure. The key is to come up with a good database structure first and then to be generous with how you use it. There's no reason why your database can't contain slabs of HTML itself, so that some instances of a page format entirely differently (an obvious one here is to use different style sheets, or different header and footer SSIs).
A slick, database-driven website without being a guru of the arcane technologies that run on UNIX web servers?